Proof of Exclusion: A Smart Contract Bloom Filter
Introduction
Smart contracts operate in highly constrained environments.
We often need to use clever data structures to achieve particular goals within the confines of the virtual machine.
A common requirement is to prove membership of something.
For example, you might need to prove that your account has been whitelisted in order to claim an NFT. This is called an inclusion proof, and it can be implemented efficiently with a merkle tree.
But sometimes you need the opposite - to prove that an element is not a member of a set.
Imagine you are building a dapp that allows users to register on chain.
Each user should be able to choose their own username when they sign up, but the contract needs to guarantee that usernames are unique.
Is there a way to prove that a username hasn't already been taken, without storing every single value on chain?
Bloom Filters
Bloom filters are space-efficient probabilistic data structures.
They can be used to check whether an element is a member of a set, without needing to store the set itself.
What's fascinating, in light of the efficiency, is that bloom filters have no false negatives.
They can prove with certainty that an element is not a member of a set.
But false positives are possible.
If we query a bloom filter to check whether element $a$ is in set $X$, the answer will either be 'probably' or 'definitely not'.
Thinking back to the username scenario - a bloom filter can guarantee that each username is unique.
The trade-off is that a small number of usernames will be denied even though they have not been taken.
How It Works
Let $U$ be the set of usernames registered:
$$U = \{u_1,u_2,...,u_n\}$$
We construct an array of $m$ bits, with each bit initially set to zero.
A traditional Bloom filter uses $k$ independent hash functions \(h_1,...,h_k\).
$$\forall i \in \{1,...,k\}, \ h_i : U \to \{0,...,m-1\}$$
Which means the output of each hash function is a number that corresponds to an index in the array.
For each username \(u \in U\), the bits \(h_i(u)\) are set to $1$ for \(1 \le i \le k\).
Let's run through an example.
Say the first username \(u_1 = \text{satoshi}\).
We have an array of \(m = 8\) bits, with each bit initially set to zero:

And we have \(k = 3\) independent hash functions.
We apply each hash function \(h_1,...,h_k\) to username \(u_1\):
$$\displaylines{h1(u1)=5 \\ h2(u1)=7 \\ h3(u1)=0}$$
Giving three numbers in the range \(\{0,...,m-1\}\).
For each of these numbers, we set the bit at the corresponding array index to $1$:

The same bit can be set more than once, but only the first change has an effect (logical OR).
The bloom filter array now represents the set \(U = \{\text{satoshi}\}\).
So how do we check if a username is available?
If any of the bits \(h_i(u)\) are not set, then we know that username $u$ has not been registered.
Conversely, if all the bits \(h_i(u)\) are set, then we assume the username has been registered.
The reason we use multiple hash functions is to lower the collision risk.
The example shown above is trivial, but hopefully it's enough to see that there are trade-offs between time complexity, space complexity, and the probability of false positives.
Probability
Given an array of $m$ bits initially set to zero:
If we insert a single element using a single hash function, the bloom filter will look something like this:

The probability of a particular bit in the array still being zero after inserting the element is \(1 - \frac{1}{m}\), which in this case is 0.875.
But what if we use \(k = 3\) hash functions to insert the element?
The number of set bits after insertion could be 1, 2, or 3.
The probability of a particular bit still being zero after insertion is \((1 - \frac{1}{m}) ^k\), which in this case is about 0.669.
Now let's consider what happens if we insert $n$ elements.
The probability of a particular bit still being zero after insertion is:
$$(1-\frac{1}{m})^{kn} \approx e^{-kn/m}$$
If we insert \(n = 5\) elements into the array of \(m = 8\) bits, with \(k = 3\) hash functions, the probability of a particular bit still being zero at the end is about 0.134.
Now we have everything we need to calculate the probability of a false positive:
$$(1-(1-\frac{1}{m})^{kn})^k \approx (1-e^{kn/m})^k = (1-p)^k$$
Where \(p = e^{-kn/m}\).
Constraints
In reality, our choices for $k$ and $m$ are constrained by the AVM.
Version 10 supports four hash functions (as far as I'm aware):
sha256
sha512_256
sha3_256
keccak256
So $k$ has to be a whole number between one and four.
There are variations of the Bloom filter that use a single hash function, so those might be worth exploring if you need a higher $k$.
As for $m$, the maximum number of bits depends on where we store the array.
Global storage consists of key/value pairs, with a maximum of 128 bytes per pair.
So let's assume we can store a 1,000 bit array in one of those values.
Box storage is more flexible. You can store up to 32k bytes in a single box (256,000 bits).
If you need a larger array, you could of course get creative and use multiple boxes.
Ultimately it depends how many elements (e.g. usernames) we are expecting to handle.
Finding Optimal Parameters
How do we find the optimal number of hash functions $k$, such that the false positive rate $f$ is minimised?
I found this part slightly counterintuitive, because there are two contradictory forces at play.
Using more hash functions means there's a greater chance of finding a zero bit at one of the indices of \(h_i(u)\) for \(1 \le i \le k\), which decreases the rate of false positives.
But it also means that a higher proportion of bits in the array are set, which increases the rate of false positives.
The optimal value for $k$ is the one that strikes the best balance between these two forces:
$$k = \frac{m}{n} \ ln \ 2$$
A good heuristic is to choose $k$ and $m$ such that about half the bits in the array are set.
Which is the same as saying that the probability of a particular bit still being zero after inserting $n$ elements, \(p = e^{-kn/m}\), should about 1/2.
A Practical Example
Imagine we're creating a new NFT community: the Bored Algorand Yacht Club.
A smart contract will allow users to mint NFTs from the collection, until 10,000 assets have been created.
Each user who mints an NFT gets to decide the unit name for their asset.
The contract will use a bloom filter to ensure that unit names are unique across the entire collection.
To start, we define a creation method for the contract:
class BloomFilter(ARC4Contract):
"""A contract that uses a Bloom filter to ensure unit names are unique."""
@arc4.abimethod(create="require")
def new(self, max_supply: UInt64) -> None:
"""Creates a new application and initialises the bloom filter.
Args:
max_supply (UInt64): The maximum number of NFTs that can be minted.
"""
self.max_supply = max_supply
self.minted = UInt64(0)
And a method to initialise the bloom filter array:
@arc4.abimethod
def create_bloom_filter(self) -> None:
"""Initialises the bloom filter."""
_maybe, exists = op.Box.get(b"bloom")
if not exists:
op.Box.put(b"bloom", op.bzero(4096))
These two steps cannot be combined, as the contract account needs to be funded with a sufficient balance before the box can be created.
The bloom filter is initially set to an array of 4,096 bytes (32,768 bits), where each bit is set to zero.
We can work out the optimal number of hash functions using:
>>> import math
>>> m = 32_768 # Number of bits in the bloom filter
>>> n = 10_000 # Number of elements (unit names)
>>> optimal_k = m / n * math.log(2) # Optimal number of hash functions
>>> print(f"{optimal_k = }")
optimal_k = 2.2713046812588287
So we'll use two hash functions: sha512_156 and sha3_256.
These functions produce 256-bit numbers, so we need some way to map each digest to a bit index in the bloom filter array.
I'm going to cheat slightly and start by taking the last 64 bits of the digest as a uint64:
op.extract_uint64(op.sha512_256(unit_name.bytes), 24)
Because working with larger numbers is a hassle, in a smart contract.
Then, we can use modulo to map the integer to an index in the array:
op.extract_uint64(op.sha512_256(unit_name.bytes), 24) % 32_768
Let's pop this in a subroutine:
@subroutine
def to_index(digest: Bytes) -> UInt64:
"""Maps a hash digest to an index in the range [0, 32_768).
Args:
digest (Bytes): The hash digest.
Returns:
UInt64: The index.
"""
return op.extract_uint64(digest, 24) % 32_768
To mint a new NFT:
@subroutine
def mint_nft(unit_name: String) -> None:
"""Mints a Bored Algorand Yacht Club NFT.
Args:
unit_name (String): The unit name for the asset.
"""
itxn.AssetConfig(
total=1,
decimals=0,
asset_name="BAYC",
unit_name=unit_name,
reserve=Txn.sender,
).submit()
The reserve address parameter has no authority in the Algorand protocol, so it can be used for any purpose.
Here it indicates the account that minted the NFT, which could be used for validating withdrawal claims.
To purchase an NFT, a user calls the buy_nft method and provides a unit name for the asset:
@arc4.abimethod
def buy_nft(self, unit_name: String) -> None:
The contract now needs to check if this unit name has already been taken.
We start by fetching the bloom filter from box storage:
bloom_filter, exists = op.Box.get(b"bloom")
assert exists, "Application not bootstrapped"
Then hashing the unit name with functions \(h_1,h_2\):
h1 = to_index(op.sha512_256(unit_name.bytes))
h2 = to_index(op.sha3_256(unit_name.bytes))
And checking if the bits at \(h_1,h_2\) are set:
assert not (op.getbit(bloom_filter, h1) and op.getbit(bloom_filter, h2)), "Unit name already taken"
If the unit name is still available, we call the mint_nft subroutine and increment the counter:
mint_nft(unit_name)
self.minted += 1
Then, we update the bloom filter to make sure the bits at \(h_1,h_2\) are set:
bloom_filter = op.setbit_bytes(bloom_filter, h1, 1)
bloom_filter = op.setbit_bytes(bloom_filter, h2, 1)
op.Box.put(b"bloom", bloom_filter)
Putting it all together:
@arc4.abimethod
def buy_nft(self, unit_name: String) -> None:
"""Allows a user to mint anf purchase a BAYC NFT.
Args:
unit_name (String): The unit name for the asset.
"""
assert self.minted < self.max_supply, "Maximum supply reached"
bloom_filter, exists = op.Box.get(b"bloom")
assert exists, "Application not bootstrapped"
h1 = to_index(op.sha512_256(unit_name.bytes))
h2 = to_index(op.sha3_256(unit_name.bytes))
assert not (op.getbit(bloom_filter, h1) and op.getbit(bloom_filter, h2)), "Unit name already taken"
mint_nft(unit_name)
self.minted += 1
bloom_filter = op.setbit_bytes(bloom_filter, h1, 1)
bloom_filter = op.setbit_bytes(bloom_filter, h2, 1)
op.Box.put(b"bloom", bloom_filter)
Checking It Works
After compiling the contract and generating a client, we can deploy a new application as follows:
from algokit_utils import (
CreateTransactionParameters,
TransactionParameters,
TransferParameters,
get_algod_client,
get_indexer_client,
get_localnet_default_account,
transfer,
)
from smart_contracts.artifacts.bloom_filter.client import BloomFilterClient
algod_client = get_algod_client()
indexer_client = get_indexer_client()
account = get_localnet_default_account(algod_client)
client = BloomFilterClient(
algod_client,
creator=account,
indexer_client=indexer_client,
)
client.create_new(
max_supply=10_000,
)
Once the application has been created, we can transfer money to its account:
transfer(
algod_client,
TransferParameters(
from_account=account,
to_address=client.app_address,
micro_algos=100_000_000,
),
)
This is more than enough to cover the minimum balance requirement for the bloom filter box.
To initialise the bloom filter:
client.create_bloom_filter(
transaction_parameters=CreateTransactionParameters(boxes=[(0, "bloom"), (0, ""), (0, ""), (0, "")])
)
And now the application is bootstrapped.
Users can start minting NFTs from the collection.
Let's mint the first one and set the unit name to be 'The GOAT':
client.buy_nft(
unit_name="The GOAT", transaction_parameters=TransactionParameters(boxes=[(0, "bloom"), (0, ""), (0, ""), (0, "")])
)
That runs without issue, and we can verify the asset creation in Dappflow:
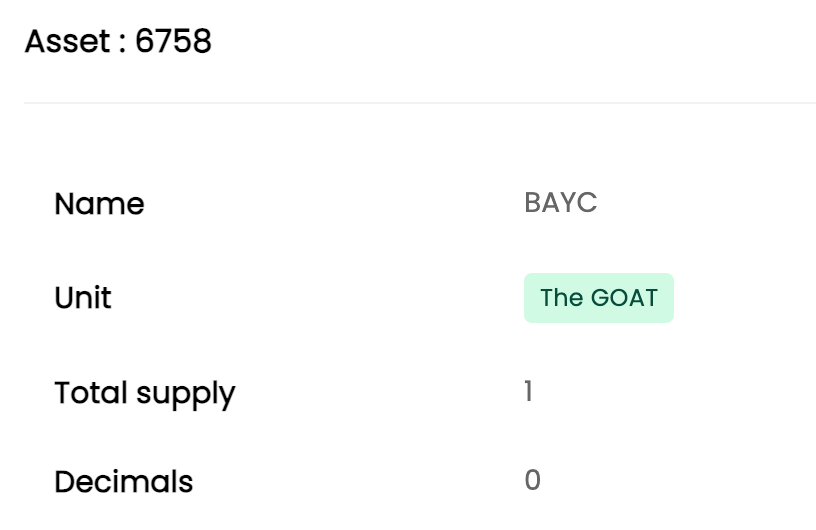
If we then try to mint a second NFT with the same unit name, we receive this error:

Perfect!
The Complete Contract Code
The code below is also available on GitHub.
# pyright: reportMissingModuleSource=false
from algopy import (
ARC4Contract,
Bytes,
String,
Txn,
UInt64,
arc4,
itxn,
op,
subroutine,
)
@subroutine
def to_index(digest: Bytes) -> UInt64:
"""Maps a hash digest to an index in the range [0, 32_768).
Args:
digest (Bytes): The hash digest.
Returns:
UInt64: The index.
"""
return op.extract_uint64(digest, 24) % 32_768
@subroutine
def mint_nft(unit_name: String) -> None:
"""Mints a Bored Algorand Yacht Club NFT.
Args:
unit_name (String): The unit name for the asset.
"""
itxn.AssetConfig(
total=1,
decimals=0,
asset_name="BAYC",
unit_name=unit_name,
reserve=Txn.sender,
).submit()
class BloomFilter(ARC4Contract):
"""A contract that uses a Bloom filter to ensure unit names are unique."""
@arc4.abimethod(create="require")
def new(self, max_supply: UInt64) -> None:
"""Creates a new application and initialises the bloom filter.
Args:
max_supply (UInt64): The maximum number of NFTs that can be minted.
"""
self.max_supply = max_supply
self.minted = UInt64(0)
@arc4.abimethod
def create_bloom_filter(self) -> None:
"""Initialises the bloom filter."""
_maybe, exists = op.Box.get(b"bloom")
if not exists:
op.Box.put(b"bloom", op.bzero(4096))
@arc4.abimethod
def buy_nft(self, unit_name: String) -> None:
"""Allows a user to mint anf purchase a BAYC NFT.
Args:
unit_name (String): The unit name for the asset.
"""
assert self.minted < self.max_supply, "Maximum supply reached"
bloom_filter, exists = op.Box.get(b"bloom")
assert exists, "Application not bootstrapped"
h1 = to_index(op.sha512_256(unit_name.bytes))
h2 = to_index(op.sha3_256(unit_name.bytes))
assert not (op.getbit(bloom_filter, h1) and op.getbit(bloom_filter, h2)), "Unit name already taken"
mint_nft(unit_name)
self.minted += 1
bloom_filter = op.setbit_bytes(bloom_filter, h1, 1)
bloom_filter = op.setbit_bytes(bloom_filter, h2, 1)
op.Box.put(b"bloom", bloom_filter)
Writing Tests
The tests below are not exhaustive - please only use them as a starting point for your own analysis:
import algokit_utils
import pytest
from algokit_utils import (
Account,
CreateTransactionParameters,
TransactionParameters,
TransferParameters,
transfer,
)
from algokit_utils.config import config
from algosdk.v2client.algod import AlgodClient
from algosdk.v2client.indexer import IndexerClient
from smart_contracts.artifacts.bloom_filter.client import BloomFilterClient
@pytest.fixture(scope="session")
def app_client(account: Account, algod_client: AlgodClient, indexer_client: IndexerClient) -> BloomFilterClient:
config.configure(
debug=True,
# trace_all=True,
)
client = BloomFilterClient(
algod_client,
creator=account,
indexer_client=indexer_client,
)
client.create_new(
max_supply=10_000,
)
transfer(
algod_client,
TransferParameters(
from_account=account,
to_address=client.app_address,
micro_algos=100_000_000,
),
)
client.create_bloom_filter(
transaction_parameters=CreateTransactionParameters(boxes=[(0, "bloom"), (0, ""), (0, ""), (0, "")])
)
return client
def test_buy_nft(app_client: BloomFilterClient) -> None:
"""Tests the buy_nft() method."""
# Mint first NFT
app_client.buy_nft(
unit_name="The GOAT",
transaction_parameters=TransactionParameters(boxes=[(0, "bloom"), (0, ""), (0, ""), (0, "")]),
)
# Make sure an error is raised when trying to mint a second NFT with the same unit name
with pytest.raises(algokit_utils.logic_error.LogicError):
app_client.buy_nft(
unit_name="The GOAT",
transaction_parameters=TransactionParameters(boxes=[(0, "bloom"), (0, ""), (0, ""), (0, "")]),
)
Acknowledgements and Further Reading
What Is a Bloom Filter? Working, Functions, and Applications by Chiradeep BasuMallick
Bloom Filters - the math by Pei Cao
Less Hashing, Same Performance: Building a Better Bloom Filter by Adam Kirsch and Michael Mitzenmacher
Compressed Bloom Filters by Michael Mitzenmacher
Bloom Filter Mathematical Proof by Humberto Villalta
Maximizing Bloom Filter Efficiency on Hardware: Unleashing the Power of a Single Hash Function by Arish Sateesan
Implementing Bloom Filters in Python and Understanding its error probability: A Step-by-Step Guide by Satish Mishra